














What do you get when you combine a pseudo‐random number generator, the sine function, and some C++ code? In this case, an album of very strange music. With a POSIX shell script and ffmpeg thrown into the mix, you also get music videos.

The album opens with Signals of Sin and closes with Signals of Sin (reprise), because of course music needs telephony signals to frame it. (These are the only two tracks that are not pseudo‐randomly generated.)
Tracks 2–10 explore what happens when you use a pseudo‐random number generator to pick the number of simultaneous “notes,” and the duration, pitch, volume, and left–right pan of each note. To create variety, some tracks (e.g., Sparse Waves of Sin) have very few simultaneous notes, while others (Way Too Many Waves of Sin) have… more. Some tracks have normal‐length notes; Super Fast Waves of Sin and Hyper Fast Waves of Sin don’t. Some tracks include harmonics (e.g., Harmonic Waves of Sin), others have only fundamentals. And for the strangest tracks (Interfering Waves of Sin and Harmonic Interfering Waves of Sin), each note is represented by a spread of interfering frequencies, instead of a single fundamental frequency and optional harmonics.
Finally, the album would not be complete without the raw output of its pseudo‐random number generator, i.e., some white noise: Dedication to Mersenne Twister 19937, Without Which This Album Would Have Been Slightly Different.
I’m definitely not claiming that this is my new favorite form of music, or even that it’s particularly consonant, but after playing around with the code and parameters a bunch, I grew to actually enjoy this music. Unlike my previous album. That one just started to grate on me more and more.
Back in 2011–2012, I played around with generating static images from mathematical functions. Each function effectively took an (x,y) coordinate and returned an RGB tuple. (By mathematical functions, I mean deterministic functions that don’t rely on external input and have no side effects. I.e., given the same input parameters, the function will always return the same value, and do nothing other than return that value.) Some scaffolding code called the function repeatedly and performed anti‐aliasing to produce an image. It was fun to see what I could do just by mapping spatial coordinates to color values.



Then earlier this year, I decided to add a time coordinate and make abstract, ambient videos using the same technique. The single‐threaded python code I used for still images was too slow to be practical for long videos, so I started from scratch with new C++ code and an improved interface. The video scaffolding code exposes the below interface for subclasses to define what the video will look like. (The use of ThreadState and TimeState does make the functional abstraction a bit less pure, but it’s important for performance to not re‐do some calculations for every sub‐pixel.) Once a subclass gives a function that defines what the video looks like in theory, the scaffolding code handles anti‐aliasing, motion blur, and rendering to turn it into a finite video that a computer can display.
// Main class to generate a video (or still frame). Subclass this. Use
// ThreadState for any information local to a thread, and TimeState for
// anything local to a single point in time. (There could be multiple
// TimeStates per frame if temporal oversampling is used.)
template <typename ThreadState = NullState, typename TimeState = NullState>
class VideoGenerator : public VideoGeneratorInterface {
…
protected:
// Get the color value at a single point in space and time. (x,y) are spatial
// coordinates, with the smaller dimension in the range [-1,1]. For a 2:1
// aspect ratio, x would be in the range [-2,2] and y in [-1,1]; for 1:2, x
// would be in [-1,1] and y in [-2,2]. t is in seconds.
virtual Rgb PointValue(
const ThreadState* thread_state, const TimeState* time_state,
float x, float y, double t) = 0;
// Override this if the per-thread state shouldn't be null.
virtual ::std::unique_ptr<ThreadState> GetThreadState() {
return nullptr;
}
// Override this if the per-point-in-time state shouldn't be null.
virtual ::std::unique_ptr<TimeState> GetTimeState(
const ThreadState* thread_state, double t) {
return nullptr;
}
…
};The first video I made was directly inspired by the last still image I’d made with the technique, and used a very similar function. For each time value t, three dimensional Perlin noise provides a map from (x,y,t) to a value that I used as the elevation of the (x,y) point on a topographic map. The elevation values are then used to make contour lines with hue denoting the elevation of the line and lightness denoting how close each point is to its nearest contour line. The code is only 43 lines long including boilerplate, and produces this 12 hour long video of gently moving colorful curves:
Next, I played around with interference patterns similar to moiré patterns, to try to generate something even more abstract than an abstracted topographic map. This code uses a set of overlapping, moving blinds to generate patterns of light and dark. The blinds use Perlin noise to independently vary their size and rotation, and to move side to side. Separately, the hue for the entire screen varies over time. Warning: the end result might cause motion sickness in some people. I tried my best to avoid it, but I’m not sure how well I succeeded.
So far, I’m finding the results of functional video generation interesting, though I do think that more traditional computer animation is a lot more versatile.
If you’re the type of person who always felt that your music collection just needed a few (hundred) more vuvuzelas, then today, you are in luck! Presenting a complete recording of Exponential Vuvuzelas, available for audio download and music video streaming today!

In addition to the music and videos, there’s also a score of the composition, the code used to turn 37 vuvuzela samples into 1024 simultaneous vuvuzelas, and the code used to generate the visual part of the music videos.
You know what the world really needs more of? Vuvuzela music. Yup. That’s totally a pressing issue in the world today. Well, I’m here to help with a new “musical” composition, Exponential Vuvuzelas. A high quality recording of this work will be released soon on my first ever full‐length album.
In the first act, the vuvuzela noisemusic starts gently, and keeps increasing as more and more vuvuzelas join in.
A lone vuvuzela plays repeatedly for some amount of time.
The vuvuzela from the previous movement continues, and one more vuvuzela joins in. This continues for some amount of time.
The vuvuzelas from the previous movement continue, and two more vuvuzelas join in. This continues for some amount of time.
The vuvuzelas from the previous movement continue, and four more vuvuzelas join in. This continues for some amount of time.
The vuvuzelas from the previous movement continue, and eight more vuvuzelas join in. This continues for some amount of time.
The vuvuzelas from the previous movement continue, and 16 more vuvuzelas join in. This continues for some amount of time.
The vuvuzelas from the previous movement continue, and 32 more vuvuzelas join in. This continues for some amount of time.
The vuvuzelas from the previous movement continue, and 64 more vuvuzelas join in. This continues for some amount of time.
The vuvuzelas from the previous movement continue, and 128 more vuvuzelas join in. This continues for some amount of time.
The vuvuzelas from the previous movement continue, and 256 more vuvuzelas join in. This continues for some amount of time.
The vuvuzelas from the previous movement continue, and 512 more vuvuzelas join in. This continues for some amount of time.
In the second and thankfully, final, act, the vuvuzelas finally go away.
The vuvuzelas from the last movement in the previous act continue to play until they run out of breath, without starting up again. The movement ends when the last vuvuzela is done.
All vuvuzelas remain silent. This lasts for as long as is needed for listeners to realize that the work is done.
As my music collection has grown, I’ve cobbled together a handful of procedures for managing it from my Ubuntu desktop. This post is primarily for my own benefit so I don’t forget parts of it, but I’m publishing it in case it’s useful to anybody else. For background, the collection is currently at 12,320 tracks, and growing. The vast majority is from (in decreasing order) CDs, vinyl records, and digital downloads. My general strategy is to save as much of any originals as possible in a lossless format (currently, FLAC), and generate smaller, lossy copies of the music as needed. I rely heavily on MusicBrainz for all metadata.
archive: Loosely organized files that are not for listening directly, e.g., un‐split digitized vinyl recordsmaster.rw: Well organized, master copy of the collectionmaster: Read-only view of master.rwprofiles: Various copies of the collection, derived from mastercdrdao disk-info. Sometimes there are unlisted data tracks that this discovers.archive/cd/artist-name/album-name. I manually changed its dconf setting for paranoia to ['fragment', 'overlap', 'scratch', 'repair'].archive/cd/artist-name/album-name, run cdrdao read-toc d01s01.toc (replacing d01 with the appropriate disc number) to extract the table of contents for the audio session.cdrdao read-cd --session 2 --datafile d01s02.iso d01s02.toc, replacing the disc and session numbers as appropriate, and changing the data file’s extension if appropriate.(This procedure can probably easily be adapted for tapes or other analog sources, but my experience so far is primarily with vinyl records.)
archive/vinyl/album-name, and change into it.record-vinyl project.flac to start recording audio. (Before writing record-vinyl, I had tried Audacity and Ardour for this step. Audacity froze and crashed too often, and Ardour had occasional buffer under‐runs when I did anything else with the computer at the same time. It’s definitely possible that I could have gotten either of them to work better with more effort, but the script wasn’t hard to write.)record-vinyl.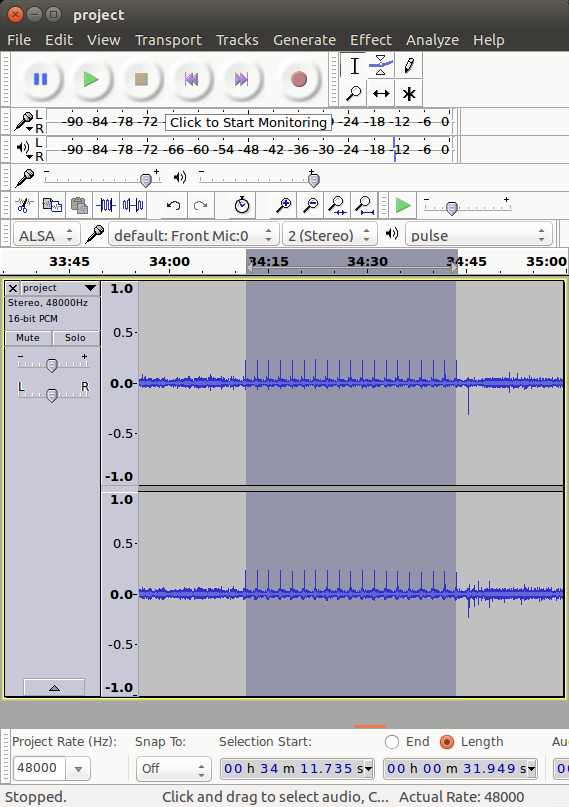

archive.archive, and make a copy for tagging and moving to master.rw.added/YYYY/MM/DD to mark when I added it to my collection, and tag tracks with context/hidden-track/pregap, context/hidden-track/separated-by-silence, or context/hidden-track/unlisted as appropriate.archive to master.rw. The rename pattern I use for moving the files is /home/dseomn/Music/master.rw/<albumartistsort>/<album>/d<discnumber|<discnumber>|XX>t<tracknumber|<tracknumber>|XX>. <artist> - <title>..mp3 or .ogg at the end of the filename.)profiles from master. (This does things like ensuring consistent cover image filenames for media players that need that, filtering out files that media players don’t understand, creating a directory with only music videos, and recoding to lossy formats for devices with limited storage.)As soon as possible after adding new music, listen to it once through. For vinyl, pay attention to make sure that the audio corresponds to the track title, and the track boundaries make sense. For CDs, listen for errors that might be correctable by washing and re‐ripping the CD. After getting more acquainted with the music over time, come back to it to add more of my folksonomy tags, then add those tags to the files with Picard.
Every once in a while, run lint-analog-audio-rips to find vinyls that I started digitizing and forgot to finish. Also, scan the entire collection with Picard to pick up relevant changes in MusicBrainz data.
I’ve been thinking a lot about backups recently. One of my multiple drives started showing signs of failure, and I had already been meaning to upgrade my backups from an rsync‐based system with no support for multiple snapshots, to something better. Of the many backup systems I’ve looked at so far, some have come relatively close to what I think backup software should do, but none are close enough. Does anybody want to help me start a company to make better open source backup software? I have some ideas for monetization, and here’s a first stab at some principles for the software:
One backup system must be able to provide backup services to multiple clients. The service should be able to support diverse types of clients, including different operating systems and different backup schedules. A client must not be required to trust any other client with anything, but it must trust the backup service with its data.
Additionally, it must be possible to configure the service so that a client does not need to trust itself in the future. E.g., it must be possible to have clients that can add new data without also being able to delete or modify any of their own data. This prevents an attacker who compromises a client from being able to compromise backups made from that client prior to the compromise.
Backed up data should outlive any people involved in creating it. There must not be any single points of failure in accessing (but not necessarily in adding) backed up data. It must be possible to maintain offline copies of backups in relatively inaccessible and secure locations. It must be possible to maintain online copies in places that can’t run custom software, e.g., cloud storage. It must be possible to access data long after this software stops being maintained.
Any data format changes must include upgrade paths. Wherever cryptographic, compression, chunking, or other algorithms are used in ways that affect stored data, there must be a clear story for how future versions of the software can transition to newer algorithms as needed. Wherever cryptographic keying material is used, it must be possible to gradually and securely roll over to new keying material.
All software needed for reading backed up data, including all dependencies, must have source code available. Whenever possible, source code and documentation should be stored along with backed up data, to maximize the chance that data will be recoverable after this software stops being maintained. Additionally, data formats and algorithms should be chosen with the intent of making data access without a working copy of this software as easy as possible.
Data must be protected against interrupted processes, power failures, bit rot, or any other form of accidental corruption. Any attempt to access data must either succeed with the correct data, or fail loudly.
It must be possible to verify the authenticity of stored data. It must be possible to detect inauthentic modifications to authentic data, and addition of inauthentic data. It should be possible to detect replay of previously authentic data and deletion of authentic data.
A client must authenticate to a server before the client is authorized to perform any backup operations. A server must authenticate to a client before the client trusts the server with its data. Data in transit between the client and server must be verifiable.
It must be possible to encrypt stored data. [TODO: Get a better understanding of how to maintain confidentiality while also supporting incremental transfer of changed data, and update this section. Consider using random padding. Don’t forget about untrusted clients who can inject arbitrary cleartext.]
If availability and durability of data is valued over confidentiality, it must be possible to disable encryption of stored data. Additionally, it should be possible to selectively enable/disable encryption for some storage media but not others.
Data in transit must be encrypted using authenticated, ephemeral key agreement.
It must be possible to monitor the system and receive alerts about any potential problems.
Data integrity should be monitored by reading all stored data on a periodic basis, and alerting on any issues. Read or write errors during normal operation should also trigger alerts. Documentation should strongly recommend SMART monitoring, or any other sensible monitoring that might catch potential integrity or availability issues.
Per-client monitoring should be possible. E.g., the service could alert if a client has not made a backup recently enough. Ideally, it would also be possible to specify per-client backup tests that would trigger an alert on failure. E.g., a test could check that a backup contains a MySQL dump file with a timestamp close to the timestamp of the overall backup.
Per-data-copy monitoring should be possible. E.g., the service could alert if an offline medium has not been updated or verified recently enough.
The ecosystem around the backup software should be healthy. The more people who use and depend on it, the more likely backups will continue to be readable for longer without resorting to code archeology. The more import and export tools, the better. The more supported types of clients, the better. The more supported deployment environments, the better.
These principles should be followed, but they must not interfere with any primary principle. E.g., efficient network transfers must not enable one client to use the backup system as an oracle to violate the confidentiality of another client.
Ideally, the service should be able to run in a distributed mode. It should be possible to add new data to any server, and have that data propagate to all other servers. It should be possible to manage offline storage and cloud storage copies from any server.
Potentially, the service should be able to run in a multi-layer distributed mode, with distinct clusters where no single failure within a cluster affects operation of that cluster, and no single failure of an entire cluster affects operation of the entire system. E.g., a cluster could have multiple storage servers and multiple access servers. Each cluster could have an eventually-consistent, complete copy of all data, striped-with-parity across multiple storage servers. Any access server could operate on data within its cluster, replicate data to/from an access server in another cluster, and accept new backups from clients.
Resources should be used efficiently. Data should be deduplicated. Unchanged data shouldn’t be sent over the network unnecessarily. It should be possible to specify a retention policy for when old data is deleted. Resuming an interrupted transfer should be possible.
It should be easy to add or remove a client, to swap drives, etc. Ideally, initial setup would also be easy. There should be a mode where the client and server are bundled together.
Hard drives, solid state drives, and cloud storage should be the primary targets. Tapes, optical media, and any other reasonable storage media should also be supported, at least to a limited extent. For example, it might be reasonable to require low seek latency for creating a new backup, but support bulk copying to tapes or optical media after the backup is created. To the extent possible, all media should support integrity verification in a single pass, and extraction of a complete set of or subset of data in a single pass.